An Analysis of the JavaScript Package Ecosystem npm
Originally published at:http://www.apiful.io/intro/2016/06/01/npm-analysis.html
In our research, we primarily focus on supporting the provision and consumption of Web APIs - API Harmony is the embodiment of these efforts. One question in this context is whether we can recommend popular, uprising packages or SDKs used in relation with Web APIs. Thus, we recently looked into data available on packages in the JavaScript ecosystem npm, which led to quite a bit of research on that topic and ultimately a paper that I just presented at the MSR conference. A pre-release version of the paper - containing all details and many analyses - is available here.
An HTML version (that looks like the original paper) is available here (created with pdf2htmlEX).
The official version of the paper is available at the ACM digital library.
The JavaScript ecosystem npm
In recent years, JavaScript has emerged to become one of the ubiquitous programming languages of our time. A recent study performed on StackOverflow and statistical data collected from GitHub show it to be the most commonly used programming language. Reasons for this success are arguably the creation of Node.js, built on top of Google's V8 JavaScript engine, and the early creation of the node package manager (npm), which made publishing and using JavaScript packages a breeze. While originally targeted at backend modules for Node.js primarily, by now tools like Browserify or webpack enable the convenient usage of npm-hosted packages in client-side applications as well. As of writing this blog post, npm hosts over quarter of a million packages. So what better place to start researching means to recommend packages / SDKs? Together with my colleagues Philippe Suter and Shriram Rajagopalan I went to explore npm.
Collecting data
Our efforts started with the motivation to learn about ways to recommend packages / SDKs. The data we collected reflect this goal: First, we obtained package.json descriptions for the around 185 thousand packages that existed in September 1st 2015 from npm's registry. npm exposes not only the latest package.json file, but a timestamped one for every version of a package ever released. Next, we used npm's API to obtain a history of daily download figures for packages. Finally, we used data from the GHTorrent project to collect package.json files of around 115 thousand JavaScript applications hosted on GitHub. These applications are not npm packages themselves. Using the Git history, we collected their versions created over time. Having all this data at hand, it was time to do some analyses. In the following, we only present selected results. For more details, please refer to our paper.
Ecosystem evolution
A first set of analyses concerns the evolution of npm as an ecosystem. Figure 1 shows the superlinear growth of npm both with regard to number of packages (blue line) and number of dependencies (green line). Furthermore, we see that the average number of dependencies specified per package is also growing, if not in a superlinear way (red line).
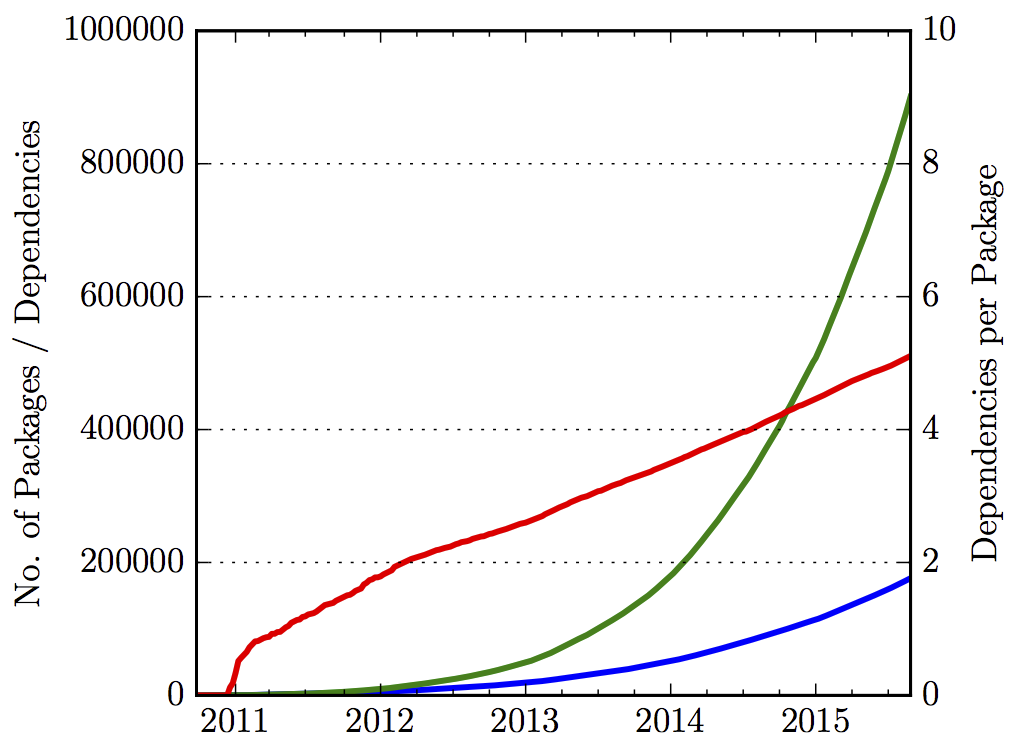 Figure 1: Packages (blue), overall dependencies (green), and avg. dependencies per package (red) in npm over time
Figure 1: Packages (blue), overall dependencies (green), and avg. dependencies per package (red) in npm over time
Interestingly, while the number of dependencies specified per package continuously rises, there remains a relatively fixed ratio of packages on npm that are depended upon. Figure 2 shows, over time, the percentages of packages that are depended upon by different numbers of other packages. The graph indicates a power-law distribution, where a comparatively small percentage of packages is depended upon very frequently, whereas the large number of packages is not depended upon at all.
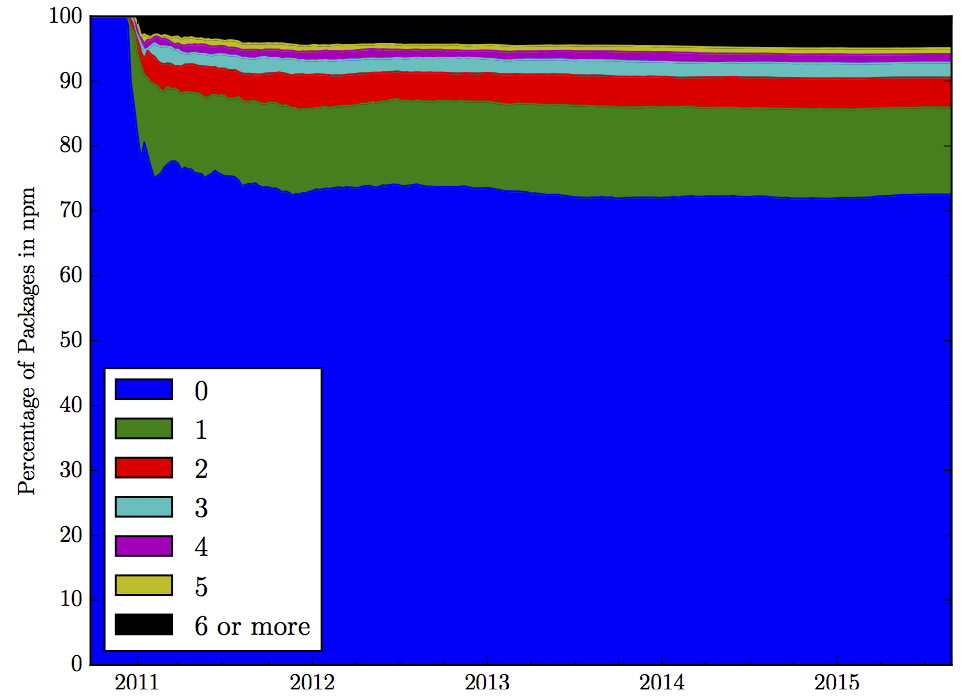 Figure 2: Characterizing packages in npm by the number of packages depending on them
Figure 2: Characterizing packages in npm by the number of packages depending on them
PageRank over time
Next, and coming back to our original motivation, we assessed ways to describe package popularity. Having package.json files for all versions of packages, we can reconstruct the npm dependency graph at any point in time point (we have data spanning October 1st 2010 to September 1st 2015). Doing so allows us to use graph measures like PageRank to compute the importance of packages. Applying PageRank on a weekly basis allows to follow how package popularity evolves. For example, figure 3 shows the inner-npm PageRank of selected utility libraries. Here we see, for example, how Underscore.js remained one of the highest ranked packages in npm since its publication. Basically all other utility libraries tend to tank in popularity. The exception is lodash, which originally mimicked Underscore's API and was actually able to overtake it with regards to PageRank in May 2015.
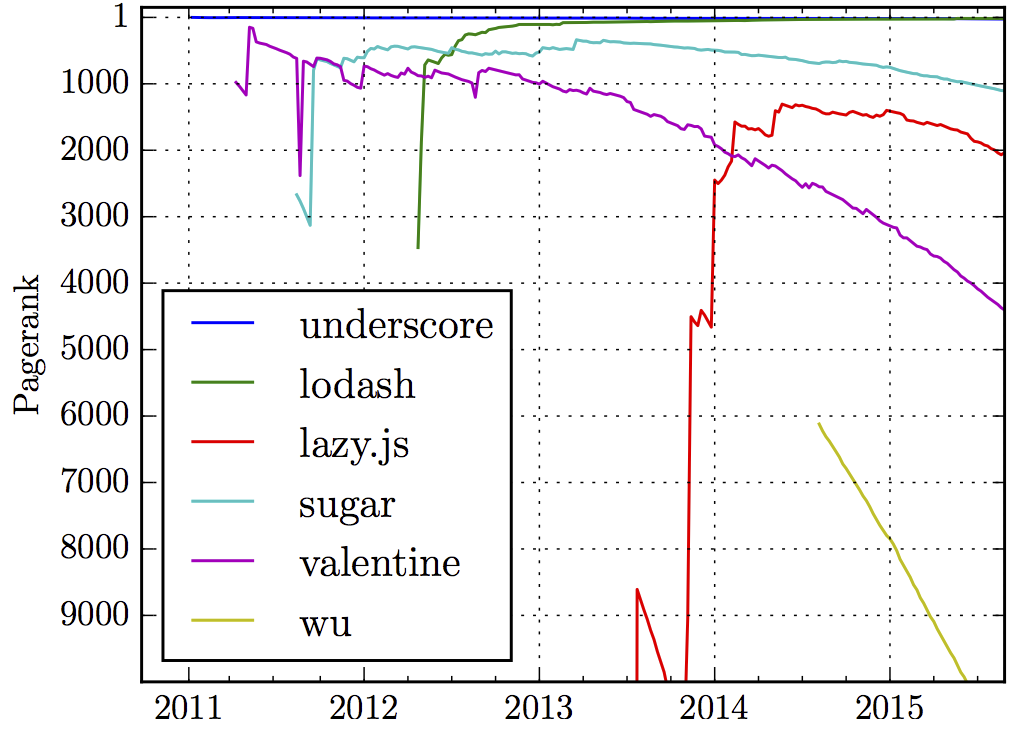 Figure 3: PageRank of selected utility packages on npm over time
Figure 3: PageRank of selected utility packages on npm over time
Complexities of package popularity
In addition to PageRank, we also assessed package popularity with regards to the number of downloads and with regards to the number of dependencies from JavaScript applications mined from GitHub. One interesting insight is that these measures do not predict popularity in the same way. While the three popularity measures are positively correlated, their correlation is not strong. To look into this, we focused on the two measures PageRank and number of dependencies from GitHub applications. We selected two sub-sets from the data: "npm strong" are the 1000 packages that perform best in PageRank as compared to the number of dependencies from GitHub applications. On the other hand, "GitHub strong" are the 1000 packages that perform best in number of dependencies from GitHub as compared to their PageRank. To assess the nature of packages in these two sets, we looked at their keywords, specified in the package.json files. Figure 4 shows that there seems to be a qualitative difference between packages in these two sets: "npm strong" packages tend to address lower-level capabilities like "buffer" or "array" - they are primarily used as building blocks for other packages. On the other hand, "GitHub strong" packages tend to address application-level capabilities, like "gulp", "express", or "authentication". This finding is very revealing for us, because it implies that package recommendation should consider the context of the development project: one might want to recommend different packages depending on whether someone is building an application or another package!
 Figure 4: Different keywords denoting packages with either strong PageRank or high number of dependencies from GitHub
Figure 4: Different keywords denoting packages with either strong PageRank or high number of dependencies from GitHub
Versioning on npm
Finally, we also looked at the use of versions in npm. npm prescribes the use of semantic versioning. Every version should consist of a triple <major>.<minor>.<patch>. Dependencies defined in package.json files can target specific versions of a package or they can be defined in a more flexible way, resolving for example to the latest version of a package or the latest patch version for given major and minor versions. Because we have historic data on package versions from npm and historic data on dependencies from GitHub applications, we can retroactively resolve what versions of packages applications from GitHub depended upon at any point in time. We used this capability to determine the "implicit adoption ratio" of releases of a package. With implicit adoption ratio, we refer to the percentage of JavaScript applications that, when a new version of a package is released, immediately depend on that new version (at the same day).
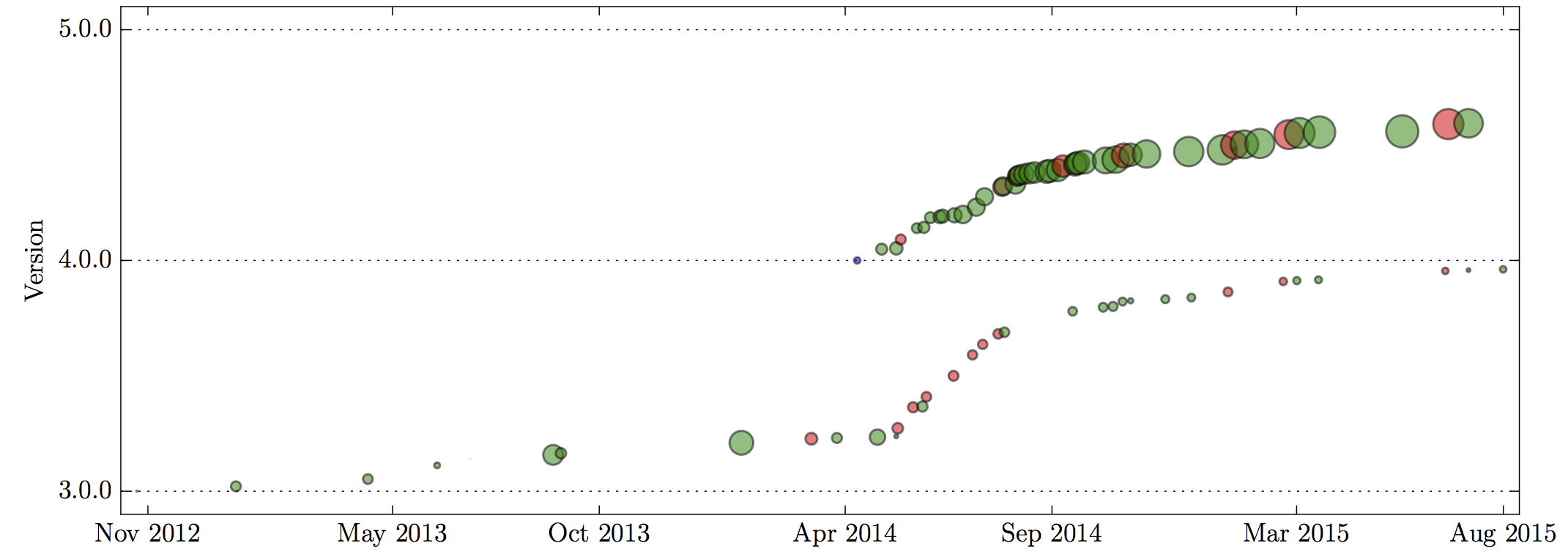 Figure 5: Implicit adoption ratios of releases of the express package. Blue circle = major release, red circle = minor release, green circle = patch release. The size of a circle indicates the implicit adoption ratio (largest: 48%).
Figure 5: Implicit adoption ratios of releases of the express package. Blue circle = major release, red circle = minor release, green circle = patch release. The size of a circle indicates the implicit adoption ratio (largest: 48%).
Figure 5 illustrates selected releases of the Express application framework. Every circle represents a release. The color of the circle states the nature of the release, being either major, minor, or patch. Finally, the size of a circle indicates the implicit adoption ratio of the release. The figure shows that with the release of the major version 4, following Express releases targeted both major version 3 and 4. Since the release of version 4.0.0, the implicit adoption ratios for releases targeting major version 4 have gradually grown. In fact, in summer 2015, a value as high as 48% can be observed. That is, on the day of the release, nearly half of the JavaScript applications immediately resolved to the latest version! This shows how developers can benefit from automatic upgrades enabled by semantic versioning. In fact, we find that across all dependencies ever defined by all 115 thousand GitHub applications, every single dependency query resolved to around 1.88 versions over its lifetime!
Takeaways and outlook
When we started to look into npm, we were motivated solely by package recommendation. We quickly learned, though, that there are many aspects that can yield in interesting findings. Our paper is a first attempt to scientifically capture these findings. Since we submitted the paper for peer-reviews, the left-pad incident happened, motivating new, interesting studies. We hope there will be follow-up papers on npm and software ecosystems in general. Their findings will tell a lot about modern software development and help shape the design of related tools.